GPU加速(Graphics Processing Unit Acceleration)是指利用图形处理器(GPU)来加速特定应用程序的运行过程。GPU最初是为了处理图形渲染而设计的,但由于其高度并行化的特性,使其也能够在其他领域提供显著的性能加速,如科学计算、机器学习、深度学习等。
下面是GPU加速的一些关键概念和工作原理:
- 并行计算架构:GPU是由大量的处理单元组成的,并且这些处理单元能够同时执行多个指令,这使得GPU在并行计算任务上具有优势。GPU的并行计算能力通常通过大量的流处理器(Stream Processors)实现。
- 数据并行性:GPU加速通常涉及将计算任务分解为许多小任务,并将这些任务同时分配给GPU上的多个处理单元。这种方式被称为数据并行性,适用于那些可以独立运行的计算任务,例如矩阵运算、图像处理等。
- CUDA和OpenCL:CUDA(Compute Unified Device Architecture)是NVIDIA推出的用于GPU编程的并行计算平台和编程模型。它允许开发者使用类似C的编程语言来编写并行程序,并利用GPU的并行计算能力。OpenCL(Open Computing Language)是一种开放的并行计算框架,可用于编写能够在不同厂商的GPU上运行的并行程序。
- GPU加速的应用:GPU加速已经在许多领域得到了广泛应用,例如科学计算(如数值模拟、计算流体力学)、深度学习和机器学习(如神经网络训练)、图像处理和计算机视觉(如图像滤波、目标检测)、密码学和加密算法等。通过利用GPU的并行计算能力,这些应用程序可以获得显著的性能提升。
- GPU加速的优势:相比于传统的CPU计算,GPU加速具有更高的并行计算能力和更低的成本。GPU通常拥有数以千计的处理单元,可以同时处理大量数据,因此能够加速那些需要大量计算的任务。此外,GPU的价格通常比CPU低廉,这使得它成为高性能计算的一种经济有效的选择。
总的来说,GPU加速通过利用GPU的并行计算能力来加速特定应用程序的运行,可以显著提高计算性能和效率,同时降低成本。随着GPU技术的不断发展和普及,GPU加速将在更多的领域得到应用,并对计算机科学和工程领域产生深远的影响。
VTK 库通常会自动利用可用的GPU资源来加速渲染过程。具体来说,在大多数情况下,VTK 库会在启动时检测系统的硬件配置,并尝试使用可用的GPU进行渲染加速。
要确保启用了GPU加速,您可以执行以下几个步骤:
- 检查VTK编译选项:在编译VTK库时,确保已启用GPU加速选项。这通常是通过在CMake中设置相应的选项来完成的。
- 检查图形驱动程序:确保您的系统上安装了正确的图形驱动程序,并且它们已正确配置以利用GPU资源。
- 使用专门的渲染器:在某些情况下,您可以使用特定于GPU的渲染器来启用GPU加速。例如,VTK提供了
vtkOpenGLRenderer类,可以使用OpenGL进行渲染,从而利用GPU加速。 - 性能测试:您可以使用性能测试工具或内置的VTK性能测量功能来检查渲染速度,并确定是否已启用GPU加速。
总的来说,虽然我们在这个简单的示例中没有明确启用GPU加速,但VTK库通常会自动利用可用的GPU资源来加速渲染过程。要确保GPU加速已启用,您可以通过检查编译选项、图形驱动程序和性能测试来进行确认。
- 3D显卡是干什么的?
通过计算机的3D图形计算卡,将模型空间计算完成的结果投射到2D的显示屏上:由点线面组成封闭多边形,封闭多边形光栅化后,具有位置、颜色、法线和纹理等属性。将模型拓扑化后,赋予各种材质。最终生成的数字化的场景模型。该技术在CAD/CAM、影视动画制作、游戏制作领域使用的最多、最广泛。
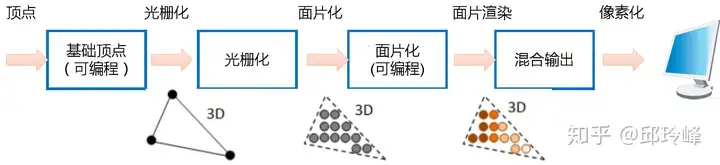
数字化的场景模型中会有上百万个点组成的物体,当鼠标旋转时(看人机交互的方式,例如VR/AR就只是用6轴加速度传感器代替鼠标控制画面旋转),场景中上百万的点同时旋转,需要的是大量并行计算能力。
而顶点旋转的公式(矩阵模型)只需要一个,将上百万个点逐个代入公式中计算,最终获得旋转后的模型显示结果。(重复工作量)
2.GPU是个什么东西,为何以前是显卡现在可以应用于那么多领域?
以前的3D显卡最主要的目的是为了在2D的显示屏中显示三维的物体。生成多边形、对多边形对象的渲染,和一些特效的处理。
CPU就是可以做不同解算公式任务的计算硬件。而显卡是只能同时重复解算一个公式的计算硬件。
有个通俗的比喻:CPU是一个博士啥都懂,显卡是千万个小学生同时计算一个公式。
CPU只能一件件的解算,显卡可以千万(上亿)个同时解算。
举个栗子:(用3D引擎原理做个模拟图形显核)
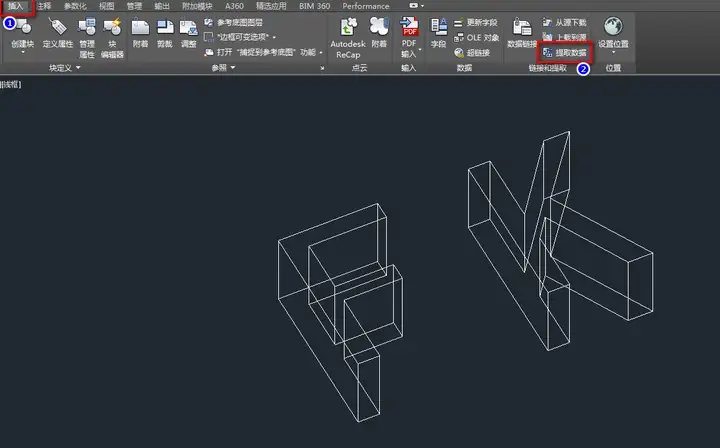
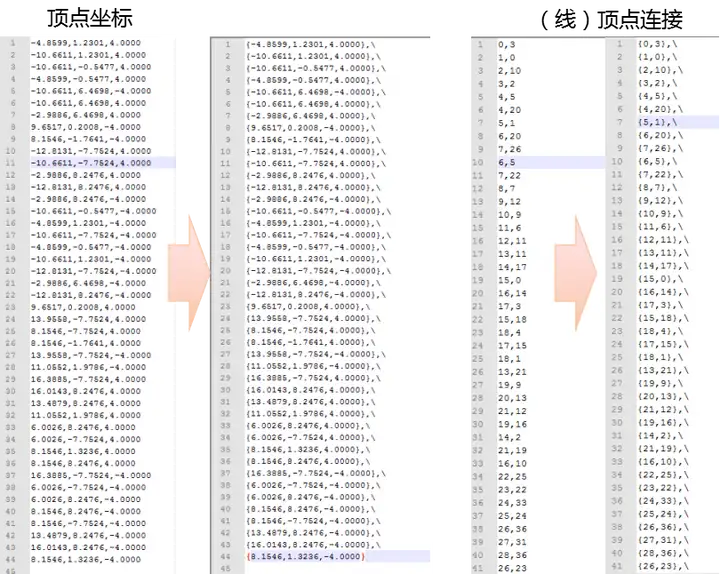
在CAD中建立模型,英文字母FK的拉伸体。使用AUTODESKCAD中的插入->提取数据,来提取模型中的直线信息。
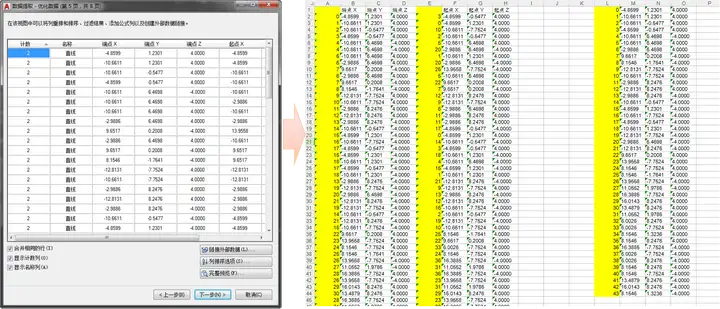
提取数据中只选择几何图形特性中的起点和端点的XYZ坐标,保存为EXCEL格式文件。因为建模打散后都是直线,导出的是点与点的连接信息,所以还需要进一步对数据筛选,删除重复坐标点,给每一个坐标设置唯一的ID号。通过比对XYZ坐标获取起点和端点的ID号,作为线段的顶点连接顺序。