

前面的话
本文将详细介绍从输入URL到页面加载的全过程
概述
从输入URL到页面加载的主干流程如下:
1、浏览器构建HTTP Request请求
2、网络传输
3、服务器构建HTTP Response 响应
4、网络传输
5、浏览器渲染页面
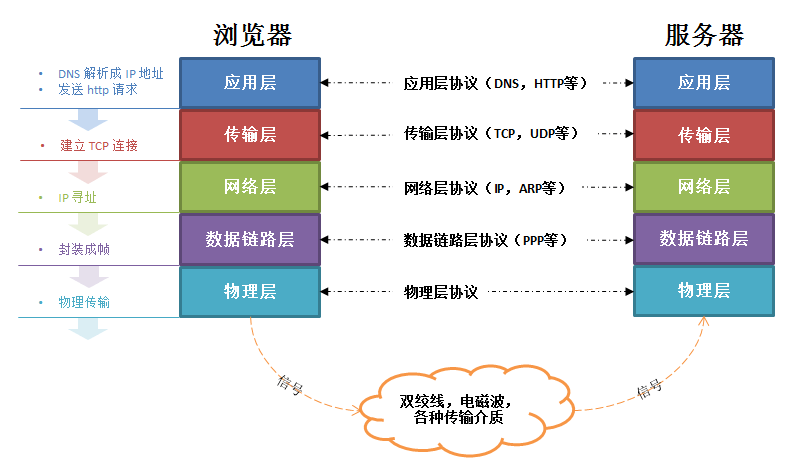
构建请求
1、应用层进行DNS解析
通过DNS将域名解析成IP地址。在解析过程中,按照浏览器缓存、系统缓存、路由器缓存、ISP(运营商)DNS缓存、根域名服务器、顶级域名服务器、主域名服务器的顺序,逐步读取缓存,直到拿到IP地址
这里使用DNS预解析,可以根据浏览器定义的规则,提前解析之后可能会用到的域名,使解析结果缓存到系统缓存中,缩短DNS解析时间,来提高网站的访问速度
2、应用层生成HTTP请求报文
接着,应用层生成针对目标WEB服务器的HTTP请求报文,HTTP请求报文包括起始行、首部和主体部分
如果访问的google.com,则起始行可能如下
GET https://www.google.com/ HTTP/1.1
首部包括域名host、keep-alive、User-Agent、Accept-Encoding、Accept-Language、Cookie等信息,可能如下

Host: www.google.com Connection: keep-alive Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8 X-Client-Data: CKm1yQEIhbbJAQijtskBCMG2yQEIqZ3KAQioo8oB Accept-Encoding: gzip, deflate, br Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
首部和主体内容之间有一个回车换行(CRLF),主体内容即要传输的内容。如果是get请求,则主体内容为空
3、传输层建立TCP连接
传输层传输协议分为UDP和TCP两种
UDP是无连接的协议,而TCP是可靠的有连接的协议,主要表现在:接收方会对收到的数据进行确认、发送方会重传接收方未确认的数据、接收方会将接收到数据按正确的顺序重新排序,并删除重复的数据、提供了控制拥挤的机制
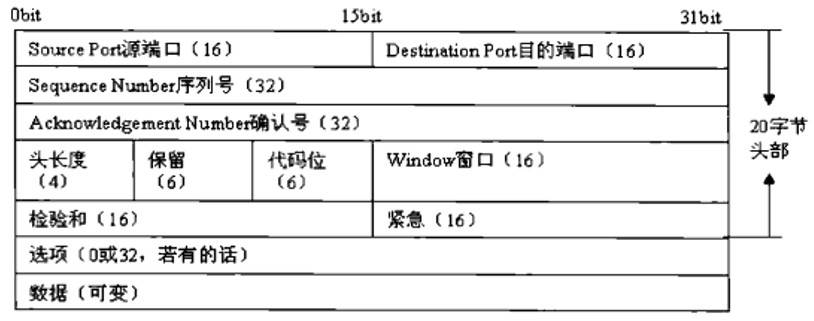
由于HTTP协议使用的是TCP协议,为了方便通信,将HTTP请求报文按序号分为多个报文段(segment),并对每个报文段进行封装。使用本地一个大于1024以上的随机TCP源端口(这里假设是1030)建立到目的服务器TCP80号端口(HTTPS协议对应的端口号是443)的连接,TCP源端口和目的端口被加入到报文段中,学名叫协议数据单元(Protocol Data Unit, PDU)。因TCP是一个可靠的传输控制协议,传输层还会加入序列号、确认号、窗口大小、校验和等参数,共添加20字节的头部信息
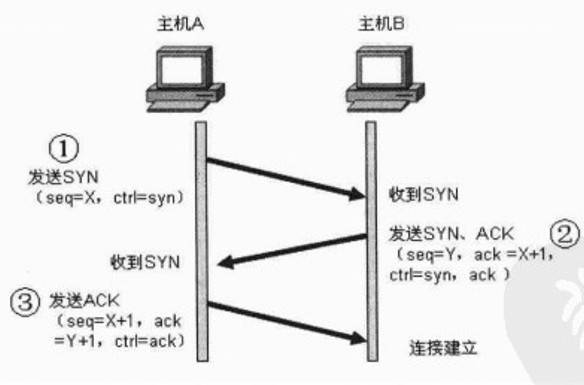
TCP协议是面向连接的,所以它在开始传输数据之前需要先建立连接。要建立或初始化一个连接,两端主机必须同步双方的初始序号。同步是通过交换连接建立数据分段和初始序号来完成的,在连接建立数据分段中包含一个SYN(同步)的控制位。同步需要双方都发送自己的初始序号,并且发送确认的ACK。此过程就是三次握手
第一次握手:主机A发往主机B,主机A的初始序号是X,设置SYN位,未设置ACK位
第二次握手:主机B发往主机A,主机B的初始序号是Y,确认号(ACK)是X+1,X+1确认号暗示己经收到主机A发往主机B的同步序号。设置SYN位和ACK位
第三次握手:主机A发往主机B,主机A的序号是X+1,确认号是Y+1,Y+1确认号暗示已经收到主机B发往主机A的同步序号。设置ACK位,未设置SYN位
三次握手解决的不仅仅有序号问题,还解决了包括窗口大小、MTU(Maximum Transmission Unit,最大传输单元),以及所期望的网络延时等其他问题
构建TCP请求会增加大量的网络时延,常用的优化方式如下所示
(1)资源打包,合并请求
(2)多使用缓存,减少网络传输
(3)使用keep-alive建立持久连接
(4)使用多个域名,增加浏览器的资源并发加载数,或者使用HTTP2的管道化连接的多路复用技术
4、网络层使用IP协议来选择路线
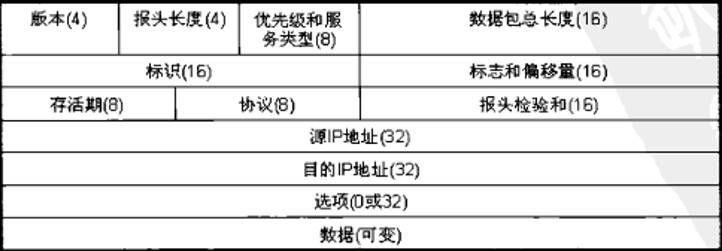
处理来自传输层的数据段segment,将数据段segment装入数据包packet,填充包头,主要就是添加源和目的IP地址,然后发送数据。在数据传输的过程中,IP协议负责选择传送的路线,称为路由功能
5、数据链路层实现网络相邻结点间可靠的数据通信
为了保证数据的可靠传输,把数据包packet封装成帧(Frame),并按顺序传送各帧。由于物理线路的不可靠,发出的数据帧有可能在线路上出错或丢失,于是为每个数据分块计算出CRC(循环冗余检验),并把CRC添加到帧中,这样接收方就可以通过重新计算CRC来判断数据接收的正确性。一旦出错就重传
将数据包packet封装成帧(Frame),包括帧头和帧尾。帧尾是添加被称做CRC的循环冗余校验部分。帧头主要是添加数据链路层的地址,即数据链路层的源地址和目的地址,即网络相邻结点间的源MAC地址和目的MAC地址
6、物理层传输数据
数据链路层的帧(Frame)转换成二进制形式的比特(Bit)流,从网卡发送出去,再把比特转换成电子、光学或微波信号在网络中传输
【总结】
上面的6个步骤可总结为:DNS解析URL地址、生成HTTP请求报文、构建TCP连接、使用IP协议选择传输路线、数据链路层保证数据的可靠传输、物理层将数据转换成电子、光学或微波信号进行传输
网络传输
从客户机到服务器需要通过许多网络设备, 一般地,包括集线器、交换器、路由器等
【集线器】
集线器是物理层设备,比特流到达集线器后,集线器简单地对比特流进行放大,从除接收端口以外的所有端口转发出去
【交换机】
交换机是数据链路层设备,比特流到达交换机,交换机除了对比特流进行放大外,还根据源MAC地址进行学习,根据目的MAC地址进行转发。交换机根据数据帧中的目的MAC地址査询MAC地址表,把比特流从对应的端口发送出去
【路由器】
路由器是网络层设备,路由器收到比特流,转换成帧上传到数据链路层,路由器比较数据帧的目的MAC地址,如果有与路由器接收端口相同的MAC地址,则路由器的数据链路层把数据帧进行解封装,然后上传到路由器的网络层,路由器找到数据包的目的IP地址,并查询路由表,将数据从入端口转发到出端口。接着在网络层重新封装成数据包packet,下沉到数据链路层重新封装成帧frame,下沉到物理层,转换成二进制比特流,发送出去
服务器处理及反向传输
服务器接收到这个比特流,把比特流转换成帧格式,上传到数据链路层,服务器发现数据帧中的目的MAC地址与本网卡的MAC地址相同,服务器拆除数据链路层的封装后,把数据包上传到网络层。服务器的网络层比较数据包中的目的IP地址,发现与本机的IP地址相同,服务器拆除网络层的封装后,把数据分段上传到传输层。传输层对数据分段进行确认、排序、重组,确保数据传输的可靠性。数据最后被传到服务器的应用层
HTTP服务器,如nginx通过反向代理,将其定位到服务器实际的端口位置,如8080。比如,8080端口对应的是一个NodeJS服务,生成响应报文,报文主体内容是google首页的HTML页面
接着,通过传输层、网络层、数据链路层的层层封装,最终将响应报文封装成二进制比特流,并转换成其他信号,如电信号到网络中传输
反向传输的过程与正向传输的过程类似,就不再赘述
浏览器渲染
客户机接受到二进制比特流之后,把比特流转换成帧格式,上传到数据链路层,客户机发现数据帧中的目的MAC地址与本网卡的MAC地址相同,拆除数据链路层的封装后,把数据包上传到网络层。网络层比较数据包中的目的IP地址,发现与本机的IP地址相同,拆除网络层的封装后,把数据分段上传到传输层。传输层对数据分段进行确认、排序、重组,确保数据传输的可靠性。数据最后被传到应用层
1、如果HTTP响应报文是301或302重定向,则浏览器会相应头中的location再次发送请求
2、浏览器处理HTTP响应报文中的主体内容,首先使用loader模块加载相应的资源
loader模块有两条资源加载路径:主资源加载路径和派生资源加载路径。主资源即google主页的index.html文件 ,派生资源即index.html文件中用到的资源
主资源到达后,浏览器的Parser模块解析主资源的内容,生成派生资源对应的DOM结构,然后根据需求触发派生资源的加载流程。比如,在解析过程中,如果遇到img的起始标签,会创建相应的image元素HTMLImageElement,接着依据img标签的内容设置HTMLImageElement的属性。在设置src属性时,会触发图片资源加载,发起加载资源请求
这里常见的优化点是对派生资源使用缓存
3、使用parse模块解析HTML、CSS、Javascript资源
【解析HTML】
HTML解析分为可以分为解码、分词、解析、建树四个步骤
(1)解码:将网络上接收到的经过编码的字节流,解码成Unicode字符
(2)分词:按照一定的切词规则,将Unicode字符流切成一个个的词语(Tokens)
(3)解析:根据词语的语义,创建相应的节点(Node)
(4)建树:将节点关联到一起,创建DOM树
【解析CSS】
页面中所有的CSS由样式表CSSStyleSheet集合构成,而CSSStyleSheet是一系列CSSRule的集合,每一条CSSRule则由选择器CSSStyleSelector部分和声明CSSStyleDeclaration部分构成,而CSSStyleDeclaration是CSS属性和值的Key-Value集合
CSS解析完毕后会进行CSSRule的匹配过程,即寻找满足每条CSS规则Selector部分的HTML元素,然后将其Declaration声明部分应用于该元素。实际的规则匹配过程会考虑到默认和继承的CSS属性、匹配的效率及规则的优先级等因素
【解析JS】
JavaScript一般由单独的脚本引擎解析执行,它的作用通常是动态地改变DOM树(比如为DOM节点添加事件响应处理函数),即根据时间(timer)或事件(event)映射一棵DOM树到另一棵DOM树
简单来说,经过了Parser模块的处理,浏览器把页面文本转换成了一棵节点带CSS Style、会响应自定义事件的Styled DOM树
4、构建DOM树、Render树及RenderLayer树
浏览器的解析过程就是将字节流形式的网页内容构建成DOM树、Render树及RenderLayer树的过程
使用parse解析HTML的过程,已经完成了DOM树的构建,接下来构建Render树
【Render树】
Render树用于表示文档的可视信息,记录了文档中每个可视元素的布局及渲染方式
RenderObject是Render树所有节点的基类,作用类似于DOM树的Node类。这个类存储了绘制页面可视元素所需要的样式及布局信息,RenderObject对象及其子类都知道如何绘制自己。事实上绘制Render树的过程就是RenderObject按照一定顺序绘制自身的过程
DOM树上的节点与Render树上的节点并不是一一对应的。只有DOM树的根节点及可视节点才会创建对应的RenderObject节点
【Render Layer树】
Render Layer树以层为节点组织文档的可视信息,网页上的每一层对应一个Render Layer对象。RenderLayer树可以看作Render树的稀疏表示,每个RenderLayer树的节点都对应着一棵Render树的子树,这棵子树上所有Render节点都在网页的同一层显示
RenderLayer树是基于RenderObject树构建的,满足一定条件的RenderObject才会建立对应的RenderLayer节点
下面是RenderLayer节点的创建条件:
(1)网页的root节点
(2)有显式的CSS position属性(relative,absolute,fixed)
(3)元素设置了transform
(4)元素是透明的,即opacity不等于1
(5)节点有溢出(overflow)、alpha mask或者反射(reflection)效果。
(6)元素有CSS filter(滤镜)属性
(7)2D Canvas或者WebGL
(8)Video元素
5、布局和渲染
布局就是安排和计算页面中每个元素大小位置等几何信息的过程。HTML采用流式布局模型,基本的原则是页面元素在顺序遍历过程中依次按从左至右、从上至下的排列方式确定各自的位置区域
简单情况下,布局可以顺序遍历一次Render树完成,但也有需要迭代的情况。当祖先元素的大小位置依赖于后代元素或者互相依赖时,一次遍历就无法完成布局,如Table元素的宽高未明确指定而其下某一子元素Tr指定其高度为父Table高度的30%的情况
Paint模块负责将Render树映射成可视的图形,它会遍历Render树调用每个Render节点的绘制方法将其内容显示在一块画布或者位图上,并最终呈现在浏览器应用窗口中成为用户看到的实际页面
主要绘制顺序如下:
(1)背景颜色
(2)背景图片
(3)边框
(4)子呈现树节点
(5)轮廓
6、硬件加速
开启硬件渲染,即合成加速,会为需要单独绘制的每一层创建一个GraphicsLayer
硬件渲染是指网页各层的合成是通过GPU完成的,它采用分块渲染的策略,分块渲染是指:网页内容被一组Tile覆盖,每块Tile对应一个独立的后端存储,当网页内容更新时,只更新内容有变化的Tile。分块策略可以做到局部更新,渲染效率更高
一个Render Layer对象如果需要后端存储,它会创建一个Render Layer Backing对象,该对象负责Renderlayer对象所需要的各种存储。如果一个Render Layer对象可以创建后端存储,那么将该RenderLayer称为合成层(Compositing Layer)
如果一个Render Layer对象具有以下的特征之一,那么它就是合成层:
(1)RenderLayer具有CSS 3D属性或者CSS透视效果。
(2)RenderLayer包含的RenderObject节点表示的是使用硬件加速的视频解码技术的HTML5 ”video”元素。
(3) RenderLayer包含的RenderObject节点表示的是使用硬件加速的Canvas2D元素或者WebGL技术。
(4)RenderLayer使用了CSS透明效果的动画或者CSS变换的动画。
(5)RenderLayer使用了硬件加速的CSSfilters技术。
(6)RenderLayer使用了剪裁(clip)或者反射(reflection)属性,并且它的后代中包括了一个合成层。
(7)RenderLayer有一个Z坐标比自己小的兄弟节点,该节点是一个合成层
最终的渲染流程如下所示:
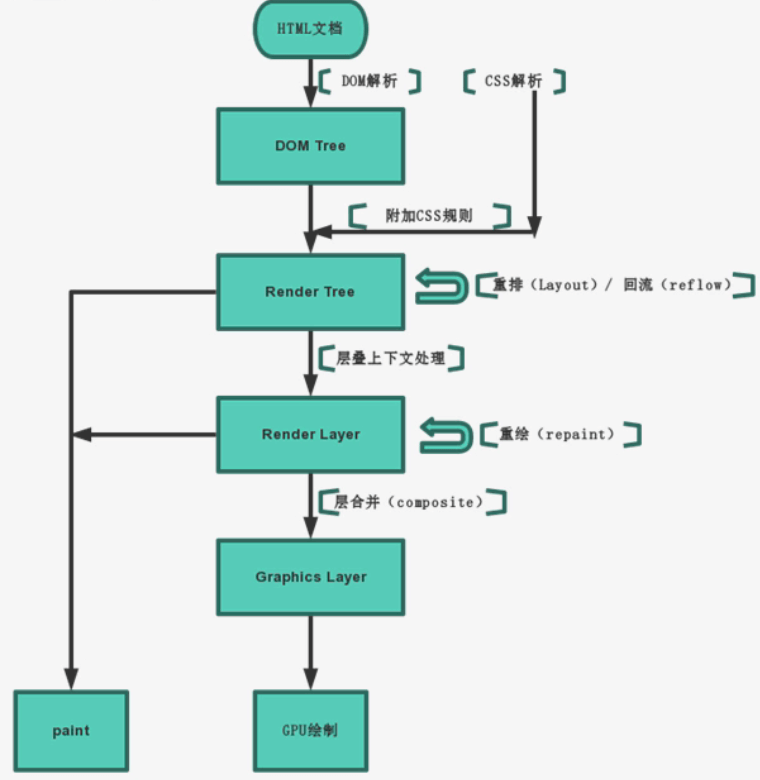
【重绘和回流】
重绘和回流是在页面渲染过程中非常重要的两个概念。页面生成以后,脚本操作、样式表变更,以及用户操作都可能触发重绘和回流
回流reflow是firefox里的术语,在chrome中称为重排relayout
回流是指窗口尺寸被修改、发生滚动操作,或者元素位置相关属性被更新时会触发布局过程,在布局过程中要计算所有元素的位置信息。由于HTML使用的是流式布局,如果页面中的一个元素的尺寸发生了变化,则其后续的元素位置都要跟着发生变化,也就是重新进行流式布局的过程,所以被称之为回流
前面介绍过渲染引擎生成的3个树:DOM树、Render树、Render Layer树。回流发生在Render树上。常说的脱离文档流,就是指脱离渲染树Render Tree
重绘是指当与视觉相关的样式属性值被更新时会触发绘制过程,在绘制过程中要重新计算元素的视觉信息,使元素呈现新的外观
由于元素的重绘repaint只发生在渲染层 render layer上。所以,如果要改变元素的视觉属性,最好让该元素成为一个独立的渲染层render layer
下面列举一些减少回流次数的方法
(1)不要一条一条地修改DOM样式,而是修改className或者修改style.cssText
(2)在内存中多次操作节点,完成后再添加到文档中去
(3)对于一个元素进行复杂的操作时,可以先隐藏它,操作完成后再显示
(4)在需要经常获取那些引起浏览器回流的属性值时,要缓存到变量中
(5)不要使用table布局,因为一个小改动可能会造成整个table重新布局。而且table渲染通常要3倍于同等元素时间
此外,将需要多次重绘的元素独立为render layer渲染层,如设置absolute,可以减少重绘范围;对于一些进行动画的元素,可以进行硬件渲染,从而避免重绘和回流

