
最近面试,遇到了一位和我讨论opus模型上下文原理的朋友(面试官)。基于讨论的内容。我补充一下相关知识和自己的思考。因为opus是闭源大模型,很多情况其实大家都不太清楚。这里也勘误几个面试官说错的问题。
问题1:长上下文实现的原理是什么?
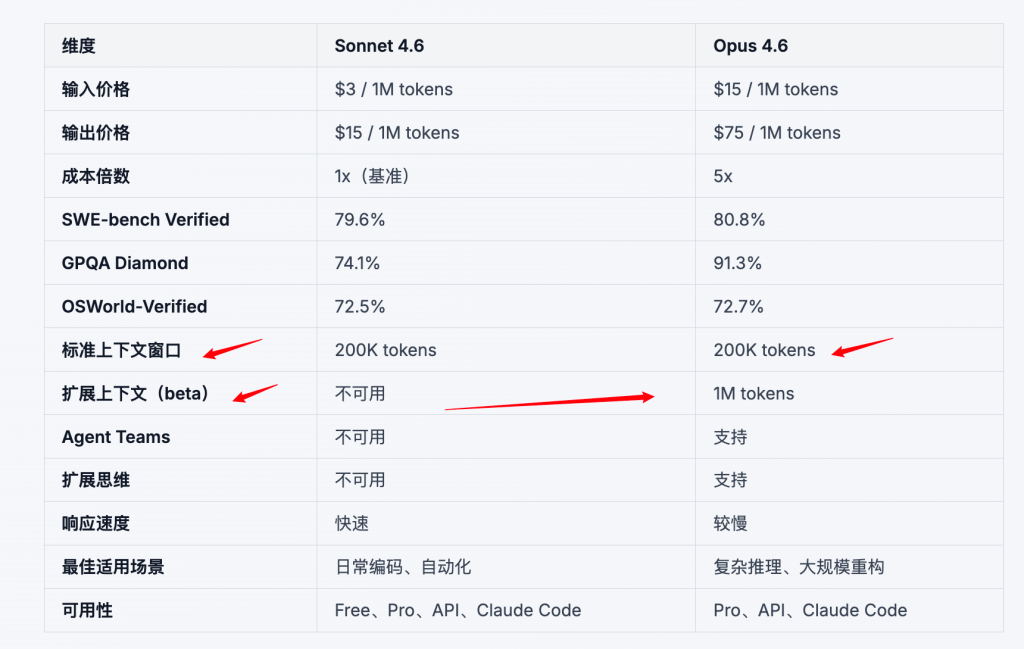
- 上下文窗口变大(能装下):Opus 4.6 把一次请求里模型可参考的“工作内存”扩展到 1M tokens。这解决的是“历史塞不进去”的问题。
- 长上下文可用性提升(用得准):即便能塞下,大模型在超长上下文里仍会出现 context rot(召回/注意力变差)。因此模型本身需要在长上下文检索与保持方面做得更稳,才能真正“用得准”。官方发布里强调了长上下文 retrieval/保持能力的提升。
- 逼近上限时的上下文管理(可持续):当对话越来越长,平台会启用 server-side compaction(上下文压缩/摘要替换),把更早的内容摘要化后替换掉,让长任务继续进行。
compaction官方文档(包含触发、compaction块、丢弃旧消息、API 配置):https://platform.claude.com/docs/en/build-with-claude/compaction- 上下文窗口与 long-context 行为说明(
context rot等背景):https://platform.claude.com/docs/en/build-with-claude/context-windows
问题2:上下文压缩是模型自主进行,还是代码调用 agent 进行?
更精确的答案是:触发与替换由平台/API完成;摘要内容由模型生成。
- 从官方
compaction文档描述来看:当输入 token 接近触发阈值时,API/服务器检测到条件并启动 compaction 流程,生成compaction块(摘要),并在后续请求中自动丢弃阈值之前的消息,只从摘要继续。 - 你在代码里通常做的只有:开启 compaction(beta header +
context_management.edits配置),以及把本轮返回的 messages(含 compaction 块)追加到下一轮。
所以它不是“需要你在 agent 里自己手动总结、再把摘要喂回模型”的那种纯应用层方案;但也不是“模型在完全无感知的平台下自己随便压缩”。更像是 平台提供的自动化上下文管理能力 + 模型负责写摘要。
Claude Opus 4.6(claude-opus-4-6)把上下文窗口扩展到 1M tokens,并且在长对话/长任务场景里通过 长上下文检索能力与 服务器端上下文压缩(compaction)来解决“能塞进去但用不准/用不起”的问题。你可以把它理解为:更大的“工作内存上限” + 更聪明的“持续工作方式”,让模型在代码库、合同/诉讼材料、长链路 Agent 任务中保持连贯。
官方来源:1M context GA 公告与 Opus 4.6 发布说明、以及 compaction / context windows 文档(文末列出)。
1. 为什么 1M context 不只是“窗口变大”
在 LLM 里,“上下文窗口”指模型在一次生成时可参考的全部文本(包括历史对话等)。窗口变大带来两个直接后果:
- 成本与延迟增长:token 越多,计算与吞吐压力越大
- 长上下文退化(context rot):即便能看到全部历史,模型对“该回忆的细节”的召回质量仍可能随长度下降
Anthropic 的工程文章把这类现象归因到注意力与训练分布带来的“有效注意力预算消耗”,因此需要做 context engineering:不是“把越多放进去越好”,而是“把最有信息密度的内容放进去,并在需要时压缩/替换”。
2. Opus 4.6 的长上下文能力:你真正得到什么
从官方发布信息看,Opus 4.6 的 1M 上下文价值主要体现在三点:
- 支持 1M tokens 上下文窗口(1M context window):比以往更大的历史可以直接纳入同一次会话工作内存
- 长上下文检索/保持能力更强:发布说明强调其在长上下文 retrieval 基准上表现提升(例如 MRCR v2 的 1M 变体,Opus 4.6 给到 76%,显著高于其前代/同级对比)
- 更适配长任务(agentic / long-running):配合工具调用与长链路任务,在不反复清空上下文的前提下持续推进
此外,1M context GA 公告里还提到一些可落地的“工程维度”:
- 标准计费适用于整个 1M 窗口(没有长上下文额外倍率)
- 媒体输入上限提升(最多 600 张图片或 PDF 页)
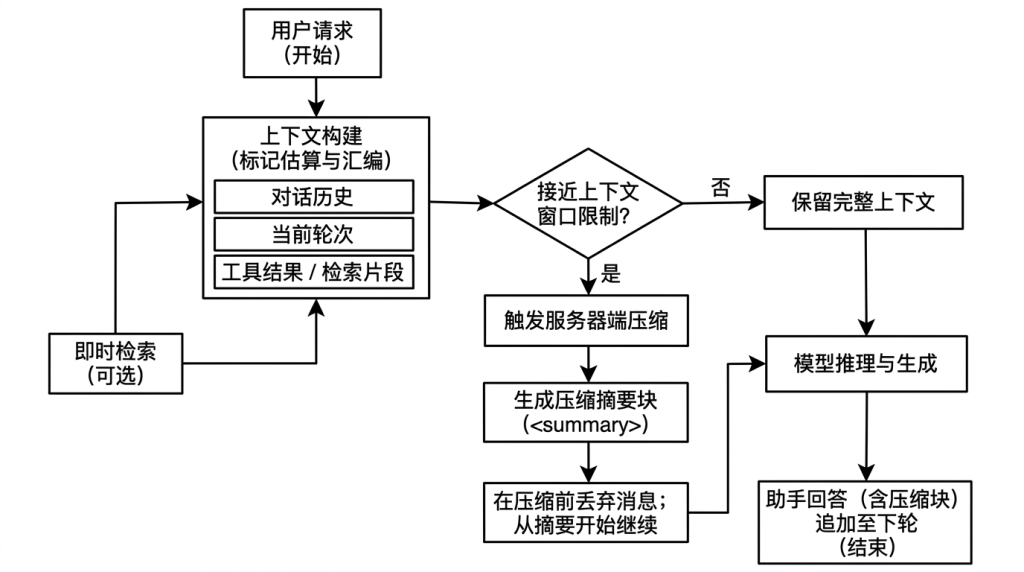
3. 关键原理:在逼近上限时自动“摘要替换”(Compaction)
如果说 1M context window 是“存储上限”,那么 compaction 就是“让长会话可持续运行的机制”。
在 compaction(服务器端上下文压缩)启用后,机制按文档描述大致是:
- 当会话接近你配置的 token 阈值时,模型会继续输出回复,同时生成一个
compaction块(摘要) - 随后的请求会自动把
compaction块之前的消息块丢弃,从摘要处继续对话
直观理解:系统把“旧的、很长的对话细节”压成“短摘要”,保留关键状态、待办、关键决策等,避免到顶后不得不清空。
3.1 触发与参数(你可以直接在 API 里控制)
Compaction 文档给出的关键参数包括:
trigger:触发压缩的条件(示例里常见为基于input_tokens的阈值,默认文档示例约在 150,000 tokens,且要求至少 50,000 tokens)instructions:自定义摘要指令(可完全替换默认摘要提示)pause_after_compaction:是否在压缩后暂停(默认false)
4. API 实战:如何在 Opus 4.6 上启用 compaction
下面以 Python 为例(字段名与文档一致),启用 compaction 并让它在接近阈值时自动压缩历史:
import anthropic
client = anthropic.Anthropic()
messages = [{"role": "user", "content": "Help me build a website"}]
response = client.beta.messages.create(
betas=["compact-2026-01-12"],
model="claude-opus-4-6",
max_tokens=4096,
messages=messages,
context_management={
"edits": [
{
"type": "compact_20260112"
# 也可以在这里加入 trigger / instructions 等配置
}
]
},
)
# 把本轮输出(包含 compaction 块)追加到 messages,便于后续继续
messages.append({"role": "assistant", "content": response.content})工程建议是:把 compaction 当作“长任务的安全绳”,而不是替代你自己的信息组织。最理想的上下文工程仍是:只把高价值内容喂进去,其他用检索/工具在需要时按需拉取。
5. 更进一步的工程策略:让 1M 变成“有效 1M”
即便有 1M 窗口和 compaction,要让长任务更稳,通常还要结合 Anthropic 的 context engineering 思路:
- 把上下文当作有限注意力预算:追求“高信息密度”,避免把大量低相关内容堆进来
- 使用 just-in-time 的上下文加载:通过工具/检索在运行时拉取相关片段,而不是一次性塞满
- 为摘要留好结构:compaction 的摘要会成为后续续写的“新起点”,因此要确保摘要能覆盖状态、下一步、关键决策(必要时用
instructions定制摘要风格)
其他问题:
- Compaction 触发条件/阈值机制?可配置吗?
到达预设的trigger阈值(通常基于input_tokens)会触发。它是可配置的:文档示例里默认/常见是约150,000 tokens,且trigger需至少50,000。 - Compaction 后会丢弃哪些内容?保留哪些内容?
后续请求会自动丢弃compaction块之前的消息块,只从compaction块里的摘要(summary)继续。保留的关键是“摘要里被写下来的状态/要点/下一步”等。 - 如何避免关键细节被压缩掉?
用instructions自定义摘要提示,要求摘要“必须保留”的粒度(例如代码片段、变量名、关键决策、待办、未解决问题)。另外做“上下文工程”:把最重要的信息用更高信息密度/结构化方式组织,降低被概括遗漏的概率。 - context rot 的具体表现是什么?1M 是否彻底消除?
随 token 增加,模型对该回忆的细节召回准确率下降,以及长距离推理可能变得不稳定(这就是 context rot)。1M 只是缓解/提升上限与检索能力,并不等于消除所有退化,所以仍需要控制上下文质量。 - 上下文压缩是模型自主还是 agent 代码做的?
触发与“把旧历史替换成摘要并接续”的流程是平台/API 的 server-side 机制。摘要文本本身由模型生成,但你在代码侧主要是开启 compaction(beta header / context_management 配置)并把返回的内容继续追加到后续 messages。 - Compaction 和工具调用(tool use)/长链路 agent 的关系?一致性会受影响吗?
对长任务而言,compaction 的目标是保持“足够的连续性”,用摘要承接状态以继续跑下去。风险在于:若摘要没有覆盖到你后续真正需要的细节,结果就可能偏;因此通常要保证摘要指令包含关键状态,并把“需要复核的证据”用检索/再次拉取补齐。 - 1M tokens 的性能/成本/延迟怎么权衡?什么时候用 1M、什么时候用检索?
成本主要随实际 token 计费;Opus 4.6 的 1M window 官方提到是不额外加长上下文溢价(标准单价覆盖整窗),但输入越长通常也会带来更高延迟与吞吐压力。用 1M:需要跨超大材料做整体依赖推理(大代码库/长合同);用检索:当只需“相关子集”时,避免噪声与 context rot。 - 什么时候用 compaction,而不是用 context editing(清空 tool/thinking 等)?
当你“经常接近上下文上限、长会话需要持续不中断”时,用 compaction 更合适(它是系统性续航)。当你只是想节省 token、清理局部冗余(例如旧 tool result、thinking block)但还能保持原细节可用时,用 context editing 更精细、更轻量。
结论:
claude opus4.6的1m上下文,其实也是语义压缩实现的,而不是模型本身具备这么长的上下文。而且上下文压缩也不是模型自动实现压缩,而且需要代码调用实现。不是模型原生能力。
你这段说法里有两点需要“拆开看”,我按更精确的口径再回答一次:
结论先说
- Opus 的 1M 上下文本质上不是“语义压缩出来的”。
1M context window指的是:在一次请求里模型可读取的工作内存上限确实扩展到约1M tokens(这是“容量”能力)。 - 上下文压缩/语义压缩对应的是 Compaction(server-side compaction):它才是在“到顶前把旧内容变成摘要,再用摘要续跑”。而且它不是你想的“模型原生一定会替你压缩到不需要任何额外动作”。
1) “1M 上下文是不是语义压缩实现?”
不是。1M context window 是直接把上下文“能放进去”的上限拉到 1M tokens。
语义压缩对应的是 compaction 这类“到阈值后替换旧历史”的机制,不是用来凭空把 200k 变成 1M 的那种“压缩等价”。
2) “上下文压缩不是模型自动实现,而需要代码调用?”
更准确地说是:
- 触发时机、摘要块写入、以及丢弃旧消息并从摘要继续:这是平台/API 的“server-side compaction”机制(你不启用/不配置,它不会凭空发生)。
- 摘要文本内容(总结):摘要本身是由模型生成的,但“生成后怎么替换历史、后续怎么接续”由 API/服务器按 compaction 规则处理。

