Linux安装ollama
外链速度非常慢,目前查询的是下面下载速度快一点。

curl -fsSL https://ollama.com/install.sh -o ollama_install.shCopy
sed -i 's|https://ollama.com/download/ollama-linux|https://gh.llkk.cc/https://github.com/ollama/ollama/releases/download/v0.5.7/ollama-linux|g' ollama_install.shCopy
chmod +x ollama_install.shCopy
sh ollama_install.shCopy
#方法二
sudo apt update && sudo apt install snapd -y
sudo snap install ollama 模型选择与下载
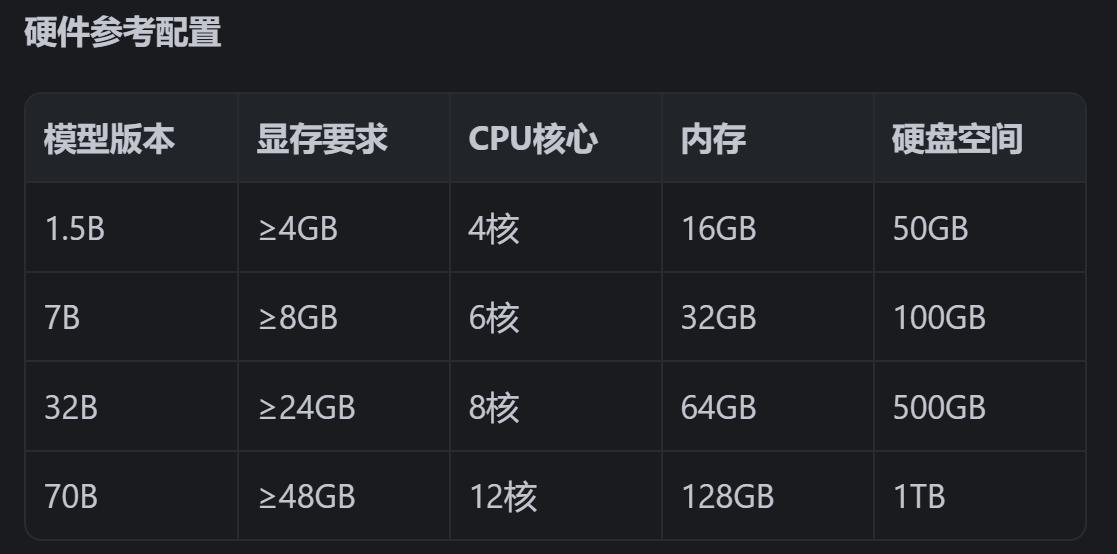
目前测试使用选择7B大小的进行使用。
运行模型与测试
curl -fsSL https://ollama.com/install.sh | sh
# 后台运行服务
sudo systemctl start ollama
# 修改监听地址(可选)
sudo systemctl edit ollama
# 添加环境变量
[Service]
Environment="OLLAMA_HOST=0.0.0.0:11434"
#建议改成127.0.0.1进行开发测试,防止流量盗用
# 重启生效
sudo systemctl daemon-reload
sudo systemctl restart ollama
# 示例:32B模型(需24G显存)
ollama pull deepseek-r1:7b
# 命令行交互测试
ollama run deepseek-r1:7b
# 输入测试问题
>>> 中国的首都是哪里?
Ollama提供了丰富的命令行工具,以下是一些常用命令:
启动Ollama服务:ollama serve
从模型文件创建模型:ollama create [模型名称] -f [模型文件路径]
显示模型信息:ollama show [模型名称]
运行模型:ollama run [模型名称] [输入文本]
从注册表中拉取模型:ollama pull [模型名称]
将模型推送到注册表:ollama push [模型名称]
列出所有模型:ollama list
复制模型:ollama cp [源模型名称] [目标模型名称]
删除模型:ollama rm [模型名称]
获取帮助信息:ollama help调用接口开发
我们的目的是,希望大模型专门回答某个范围的知识或者解释。比如,针对一个pdf,docx文件。针对某个领域,比如绘画,书法,细胞实验等。尝试打造成一个所谓的人工智能知识助手。其实就是检索增强生成(Retrieval Augmented Generation),简称 RAG,目前已经成为当前最火热的LLM应用方案。
import requests
import pdfplumber
import os
def read_pdf(file_path):
"""读取PDF文档核心内容"""
try:
content = []
with pdfplumber.open(file_path) as pdf:
for page in pdf.pages:
text = page.extract_text()
if text and text.strip():
content.append(text.strip())
return '\n'.join(content) if content else ""
except Exception as e:
raise RuntimeError(f"PDF读取失败: {str(e)}")
def deepseek_chat(api_key, question, doc_path=None, model="deepseek-chat", temperature=0.7):
"""
支持PDF文档问答的增强版函数
:param doc_path: 可选参数,PDF文档路径
"""
system_prompt = "你是CellSpace软件专属AI助手,请严格根据提供的PDF内容回答问题。"
# 读取文档内容
doc_content = ""
if doc_path:
if not os.path.exists(doc_path):
return f"文件不存在: {doc_path}"
if not doc_path.lower().endswith('.pdf'):
return "仅支持PDF格式文件"
try:
raw_content = read_pdf(doc_path)
doc_content = f"\n[PDF文档内容]\n{raw_content[:1000]}" # 截取前3000字符
except RuntimeError as e:
return str(e)
# 构造消息队列
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": f"{question}{doc_content}"}
]
# API请求配置
url = "https://api.deepseek.com/chat/completions"
headers = {"Authorization": f"Bearer {api_key}", "Content-Type": "application/json"}
data = {
"model": model,
"messages": messages,
"temperature": temperature,
"max_tokens": 2000
}
try:
response = requests.post(url, headers=headers, json=data)
response.raise_for_status()
return response.json()['choices'][0]['message']['content']
except requests.exceptions.RequestException as e:
return f"API请求失败: {str(e)}"
except KeyError:
return "响应解析异常,建议检查API版本"
# 使用示例
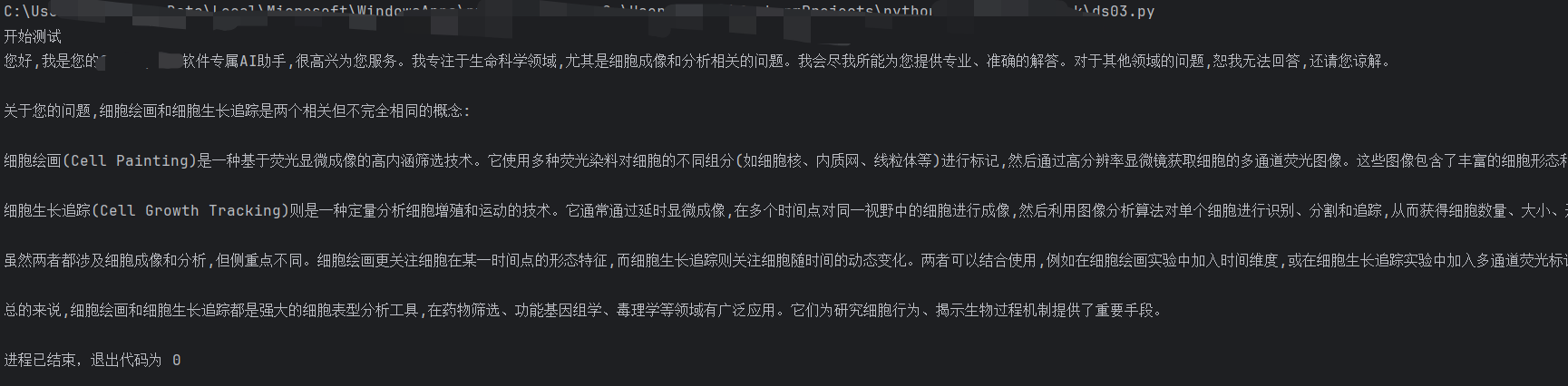
if __name__ == "__main__":
API_KEY = "sk-194a63*****************68558"
PDF_PATH = r"C:\test.pdf"
# PDF文档问答
print("开始测试")
pre_prompt = "你是我的软件专属AI助手,以女性身份先扩充自我介绍,只回答科学领域的问题,其他问题拒接回答。然后回答下面问题:"
# PDF文档问答
#print(deepseek_chat(API_KEY, "请总结PDF中的主要内容", PDF_PATH))
qus_prompt = "解释一下细胞绘画,细胞生长追踪,他们是一个意思吗?1000字以内"
# 普通问答
print(deepseek_chat(API_KEY, pre_prompt+qus_prompt))